


A fines de 2018, Facebook y Meta presentaban a Rosetta con la idea de comprender mejor las millones de imágenes que se subieron a la red social. El sistema es capaz de extraer texto y clasificar esas imágenes de forma autónoma. El problema es que esta herramienta tiene un doble filo.
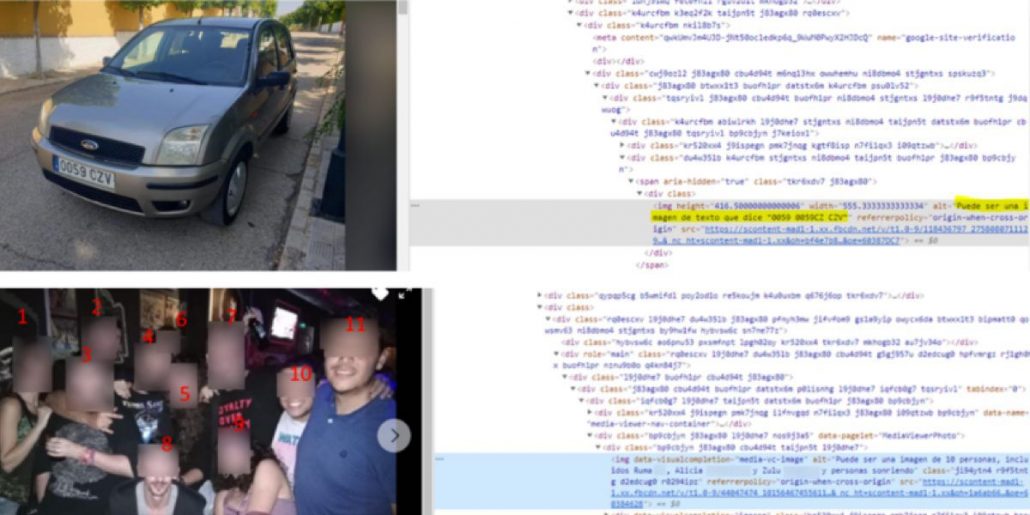
Especialistas de la empresa de investigación Molfar encontraron una función interesante en Facebook: si ingresás parte de la patente de un auto en la barra de búsqueda, vas a poder encontrar fotos de autos con patentes que contienen las letras y números que estás buscando. Esto es especialmente peligroso, por ejemplo, para los vehículos de la policía.
En un principio, Rosetta tenía como objetivo “mejorar experiencias como la búsqueda de fotos más relevantes o agregar texto a los lectores de pantalla que hacen que Facebook sea más accesible para las personas con discapacidades visuales”. La principal idea era identificar rápidamente contenido dañino e inapropiado.
El sistema de Facebook es capaz de analizar y extraer el texto diariamente y en tiempo real de más de mil millones de imágenes públicas de Facebook e Instagram e incluso de fotogramas de vídeo. En otras palabras, a cada una de estas imágenes se le añaden metadatos que la describen y que permiten etiquetarla y clasificarla fácilmente.
Frente a esto, los expertos en ciberseguridad de Quantika14, que han indicado que es posible realizar una extracción masiva de estos datos sin que Facebook pueda impedirlo. El sistema identifica cuántas personas hay en una foto -y cuántas sonríen-, si esas personas están de pie e, incluso, si están en una bicicleta.
El proceso para obtener los datos es bastante sencillo y, por eso, tan peligroso. Para obtener patentes de autos de la Policía o de una empresa simplemente hay que acceder a la página web de Facebook del objetivo, descargar los enlaces a esas imágenes y luego descargar el análisis de los textos asociados con esos textos.
Fuente: LACien








